For Feedbacks | Enquiries | Questions | Comments - Contact us @ innovationmerge@gmail.com
What?
- Due to an increase in the generation of multimedia content and audio repositories, there is a need to analyze information accurately which is present in the audio.
- Audio segmentation is a widely used application in audio analysis because it focuses on splitting an uninterrupted audio signals into segments of homogeneous content.
- The purpose of the audio segmentation is to handle different regions of audio which may have music/noise/speech/non speech etc.
- Each audio segment can be visualized as the each paragraphs in text which serves as an input to different applications.
Why?
- For analyzing and understanding an audio signal, the initial method is to distinguish and audio signal on the basis of content.
- Audio segmentation is used as a pre-processor for different applications/usecases such as
- Automatic speech recognition(ASR)
- Speaker identification
- Speaker verification
- Automatic transcription
- Audio classification
How?
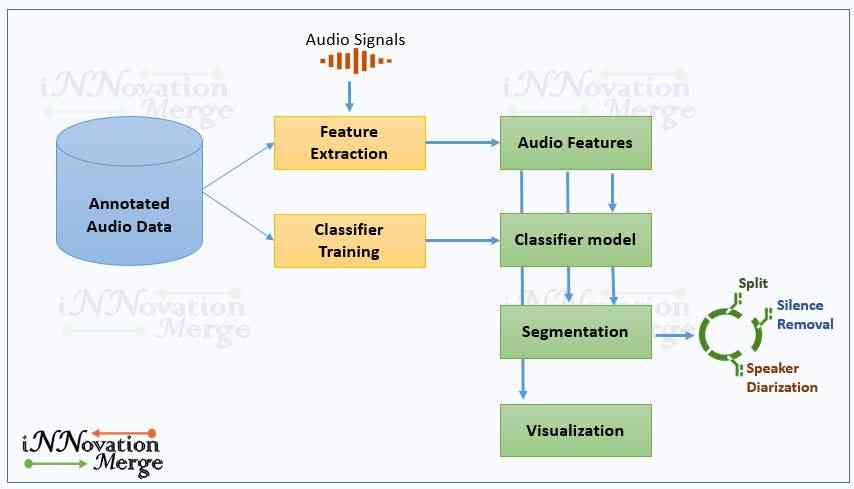
- This article explains how to segment audio into different regions using an open-source Python Library called pyAudioAnalysis.
- The library audio segmentation solutions for two general subcategories of audio segmentation:
- Supervised : These algorithms uses some kind of knowledge to classify and segment the input signals. Applications such as Audio classification will fall into this category.
* Unsupervised : These algorithms will not have any kind of prior knowledge to classify and segment the input signal. Applications such as Silence removal, speaker diarization and audio thumb-nailing will fall into this category.
- Supervised : These algorithms uses some kind of knowledge to classify and segment the input signals. Applications such as Audio classification will fall into this category.
Prerequisite
- Hidden Features of Audio Data and Extraction using Python - Part 1
- Hidden Features of Audio Data and Extraction using Python - Part 2
- Audio Classification using Machine Learning and Python
Software’s Required:
- Python 3.6
Network Requirements
- Internet to download packages
Implementation
- pyAudioAnalysis is licensed under the Apache License and it is available at GitHub- pyAudioAnalysis.
Reference
Install pyAudioAnalysis
git clone https://github.com/tyiannak/pyAudioAnalysis.git
pip install -e .Troubleshooting if error
- Error : ImportError: failed to find libmagic. Check your installation
- Solution : pip install python-magic-bin==0.4.14
- Issue resolved link
Supervised - Fix-sized audio segmentation
- Fix-sized segmentation is the simple way of segmenting an audio to homogeneous fixed-size segment.
- If there are successive segments that share a common class label then they are merged at post-processing stage.
- pyAudioAnalysis has a function mid_term_file_classification() from audioSegmentation.py which does following
- Splits an audio signal to successive mid-term segments.
- Extract mid term features.
- Classify each segment using a pre-trained supervised model.
- Merge successive fix-sized segments that share the same class label to larger segments.
- Visualize statistics regarding the results of the segmentation - classification process.
Fix-sized audio segmentation using pretrained two class SVM model(svm_rbf_sm)
from pyAudioAnalysis import audioSegmentation as aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/svm_rbf_sm", "svm", True, 'data/scottish.segments')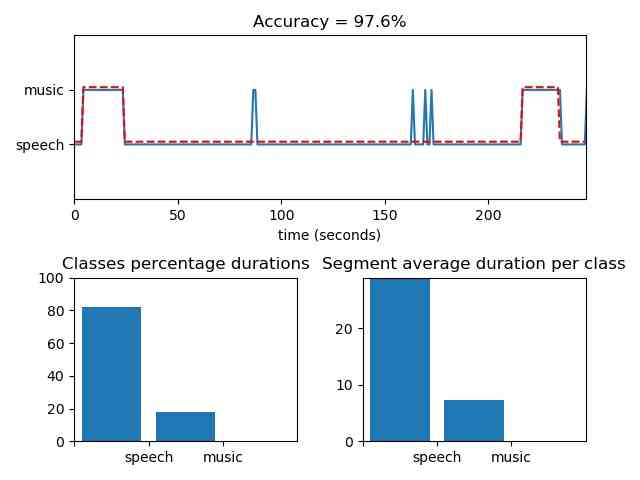
Fix-sized audio segmentation using pretrained four class SVM model(svm_rbf_4class)
from pyAudioAnalysis import audioSegmentation as aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/svm_rbf_4class", "svm", True, 'data/scottish.segments')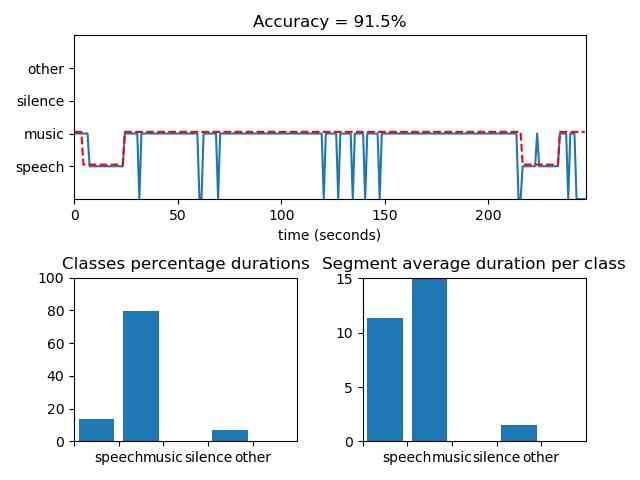
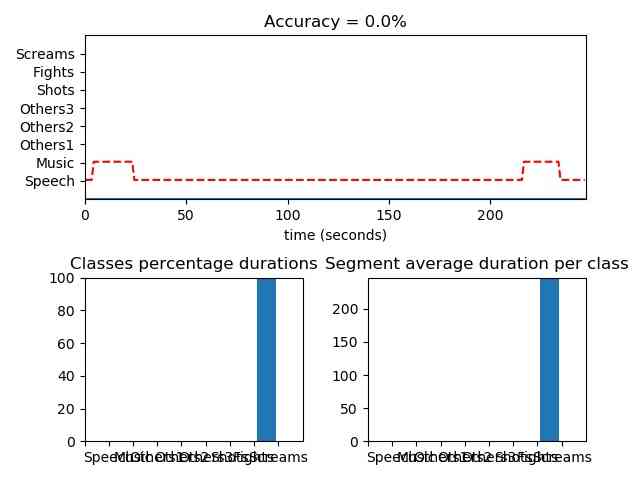
Fix-sized audio segmentation using pretrained eight class SVM model(svm_rbf_movie8class)
from pyAudioAnalysis import audioSegmentation as aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/svm_rbf_movie8class", "svm", True, 'data/scottish.segments')Fix-sized audio segmentation using pretrained Gender class SVM model(svm_rbf_speaker_male_female)
from pyAudioAnalysis import audioSegmentation aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/svm_rbf_speaker_male_female", "svm", True, 'data/scottish.segments')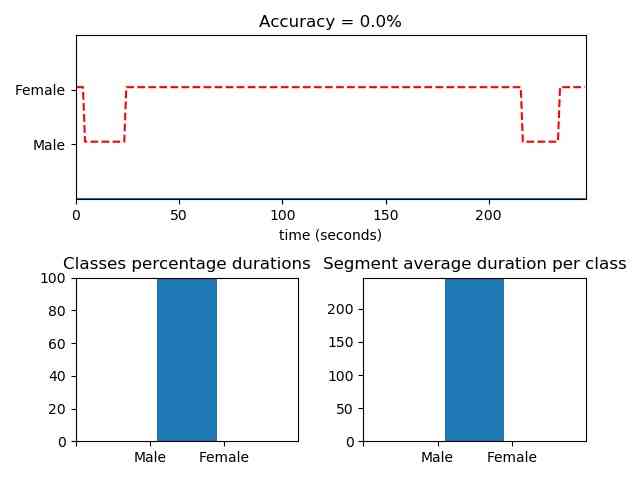
Fix-sized audio segmentation using pretrained two class KNN model(knn_sm)
from pyAudioAnalysis import audioSegmentation aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/knn_sm", "knn", True, 'data/scottish.segments')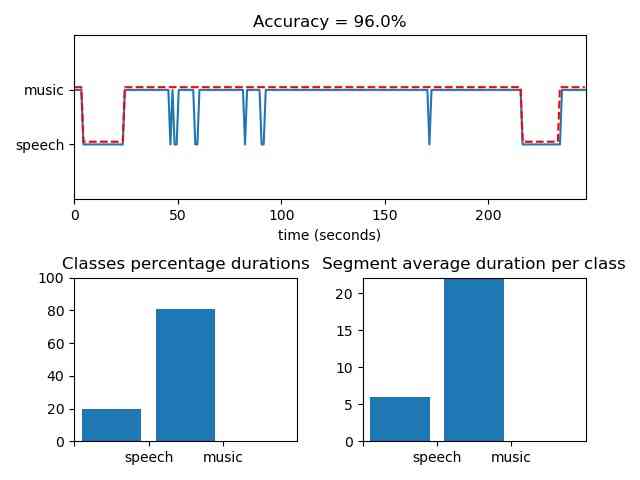
Fix-sized audio segmentation using pretrained four class KNN model(knn_4class)
from pyAudioAnalysis import audioSegmentation aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/knn_4class", "knn", True, 'data/scottish.segments')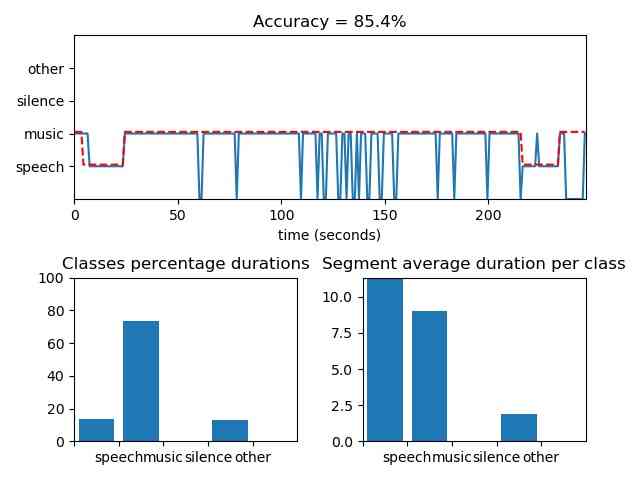
Fix-sized audio segmentation using pretrained four class KNN model(knn_movie8class)
from pyAudioAnalysis import audioSegmentation aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/knn_movie8class", "knn", True, 'data/scottish.segments')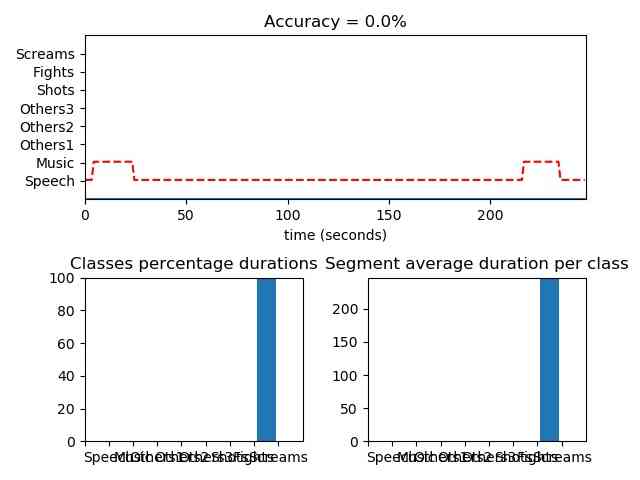
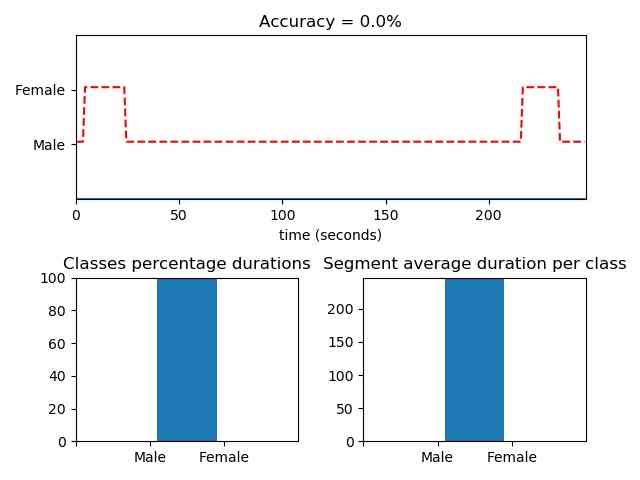
Fix-sized audio segmentation using pretrained Gender class KNN model(knn_speaker_male_female)
from pyAudioAnalysis import audioSegmentation aS
[flagsInd, classesAll, acc, CM] = aS.mid_term_file_classification("data/scottish.wav", "data/models/knn_speaker_male_female", "knn", True, 'data/scottish.segments')Supervised - HMM-based audio segmentation
Hidden Markov models are generative models that follow transitions among states based on probabilistic rules.
When the HMM arrives at a state, it emits an observation, which in the case of signal analysis is usually a continuous feature vector.
HMMs can be used for recognizing sequential labels based on a respective sequence of audio feature vectors.
pyAudioAnalysis provides the ability to train and apply Hidden Markov Models (HMMs) in order to achieve joint classification-segmentation. This is a supervised approach, therefore the required transition and prior matrices of the HMM model need to be trained.
Once the model is trained, function hmm_segmentation() can be used to apply the HMM
Example using pretrained hmmRadioSM
from pyAudioAnalysis import audioSegmentation as aS aS.hmm_segmentation('data/scottish.wav', 'data/hmmRadioSM', True, 'data/scottish.segments')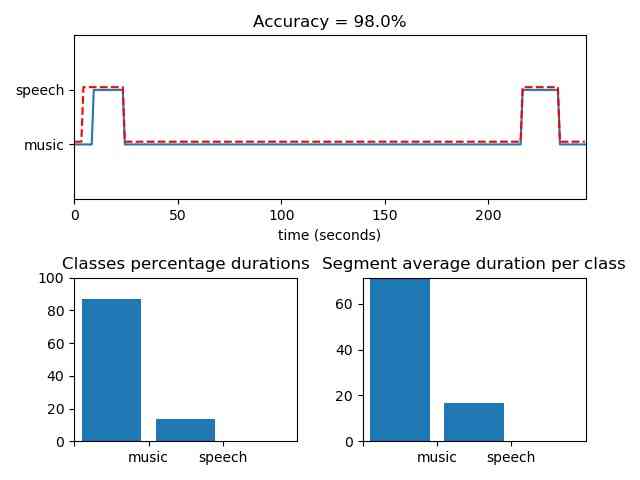
Other Features
- Unsupervised - Silence Removal, Speaker Diarization, Audio Thumbnailing will be covered in Part 2

{kind=link}
{kind=link}