For Feedbacks | Enquiries | Questions | Comments - Contact us @ innovationmerge@gmail.com
What?, Why?
Software’s Required:
- Python 3.6
Network Requirements
- Internet to download packages
Prerequisite
- Hidden Features of Audio Data and Extraction using Python - Part 1
- Hidden Features of Audio Data and Extraction using Python - Part 2
- Audio Classification using Machine Learning and Python
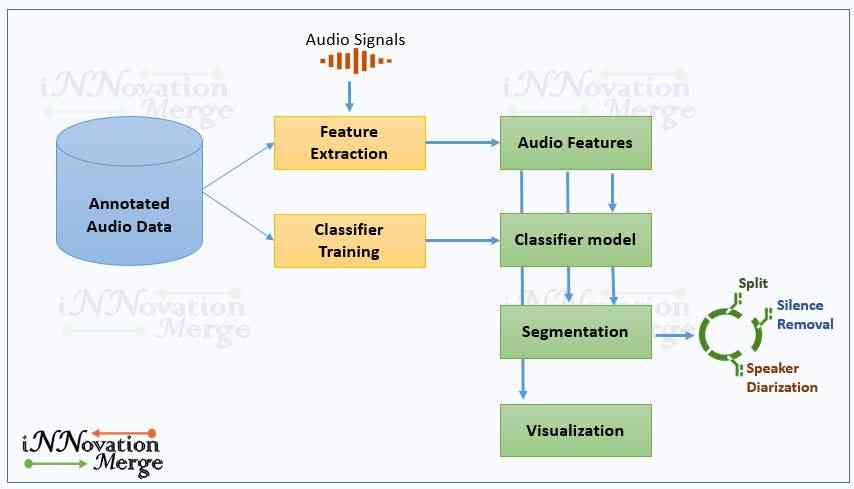
How?
Implementation
- pyAudioAnalysis is licensed under the Apache License and it is available at GitHub- pyAudioAnalysis.
Reference
Install pyAudioAnalysis
git clone https://github.com/tyiannak/pyAudioAnalysis.git
pip install -e .Troubleshooting if error
- Error : ImportError: failed to find libmagic. Check your installation
- Solution : pip install python-magic-bin==0.4.14
- Issue resolved link
Unsupervised - Silence removal
- pyAudioAnalysis has semi-supervised silence removal function which takes an uninterrupted audio data and provides response with segment endpoints that correspond to individual audio events, removing silent areas of the audio.
- This is achieved by following steps
- SVM model will be trained to distinguish between high-energy and low-energy short-term frames.
- Whole audio data is passed to the SVM classifier which results in a sequence of probabilities that correspond to a level of confidence that the respective short-term frames belong to an audio event.
- A dynamic thresholding is used to detect the active segments.
from pyAudioAnalysis import audioBasicIO as aIO
from pyAudioAnalysis import audioSegmentation as aS
[Fs, x] = aIO.read_audio_file("data/recording1.wav")
segments = aS.silence_removal(x, Fs, 0.020, 0.020, smooth_window = 1.0, weight = 0.3, plot = True)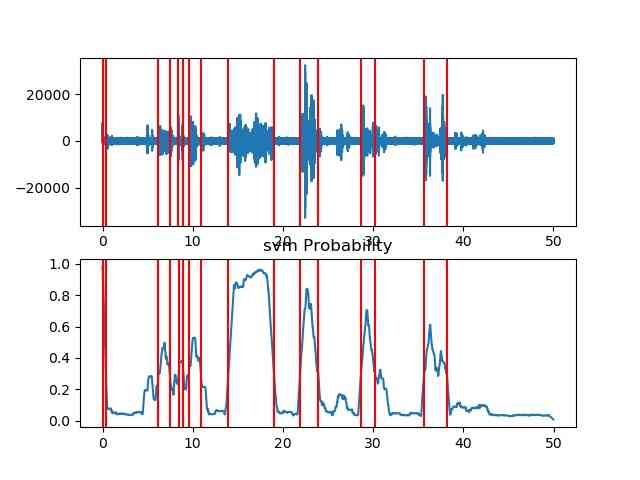
Unsupervised - Speaker Diarization
Speaker diarization is the process of identifying “who spoke when” in the audio provided automatically.
Speaker diarization needs both segmentation and clustering, where speech segments are grouped into speaker-specific clusters.
Following are the main algorithmic steps performed to implement diarization
- Feature extraction (short-term and mid-term)
- FLsD step (optional)
- K-means clustering
- Smoothing
from pyAudioAnalysis import audioSegmentation num_speakers = 4 audioSegmentation.speaker_diarization("data/diarizationExample.wav", num_speakers, plot_res=True)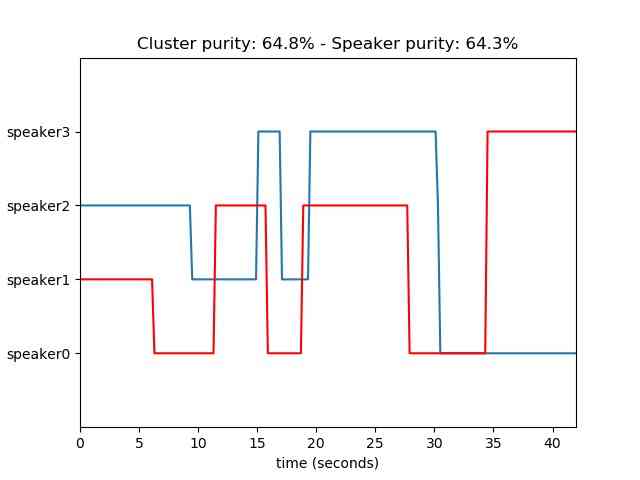
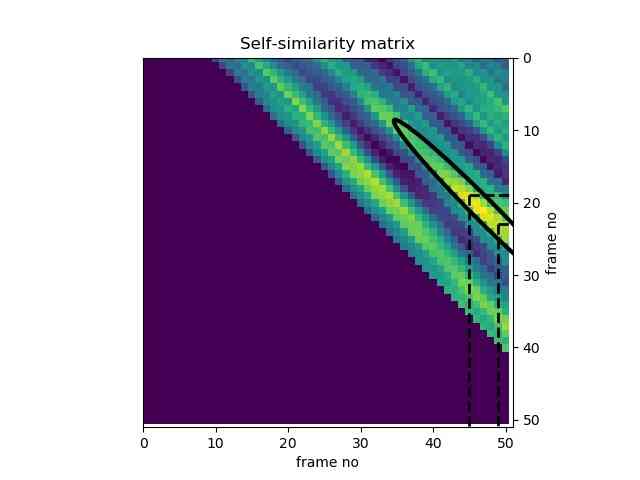
Unsupervised - Audio thumbnailing
Audio thumbnailing refers to the unsupervised extraction of the most representative part of a music recording such as chorus, music.
In pyAudioAnalysisLibrary this has been implemented in the musicThumbnailing function.
The automatically annotated diagonal segment represents the area where the self similarity is maximized, leading to the definition of the “most common segments” in the audio stream.
from pyAudioAnalysis import audioAnalysis thumbSize = 25 audioAnalysis.thumbnailWrapper("data/recording1.wav",thumbSize)