For Feedbacks | Enquiries | Questions | Comments - Contact us @ innovationmerge@gmail.com
Prerequisite
What?
Object detectionis a computer vision task that detects and finds things of interest in an image or video.Object detection'spurpose is to not only categorize all of the objects in the input data, but also to construct bounding boxes around each identified object to show its spatial location.Object detectioncan be used for a variety of purposes, including pedestrian detection, face detection, vehicle detection, and many others. It is an essential component in a wide range of computer vision systems, including autonomous vehicles, surveillance systems, and image-based search engines.- In this article, we will be using Object detection for the purpose of Predictive Capture.
Predictive Captureinstantly captures photos, As soon as an object enters the camera frame. - Combining the “object detection” and “predictive capture” concepts, device will predict when an object of interest is about to enter the frame and then automatically captures a photo at that moment.
Why?
Predictive capture proves beneficial in scenarios where you want to capture specific objects like people, cars, animals, etc., as it automatically takes photos of these subjects, storing them for convenient and speedy review.
Advantages of Predictive Capture:Instantaneous Capture:Predictive capture swiftly captures the target objects the moment they appear in the camera frame.Ideal for Dynamic Scenes:Well-suited for fast-paced or unpredictable situations, predictive capture excels in scenarios where subjects may move rapidly.Reliable Object Detection:The underlying object detection algorithms ensure accurate identification of specific objects of interest, minimizing false captures.Easy Review Process:The automatically saved photos allow for a quick review, enabling you to select the required images without going through a lengthy video recorded by CCTV or any other security systems.Versatility:The feature is flexible and can be adapted to various environments and subjects, ranging from portraits to wildlife photography.Increased Success Rate:Predictive capture significantly increases the chances of capturing the desired object, enhancing the overall quality of the photo collection.Fun and Engaging:Using predictive capture can add an element of excitement and surprise, as users discover moments they might have otherwise overlooked.
How?
Software’s Required:
Network Requirements:
- Internet to download packages
Implementation:
Popular object detection algorithms
Region-based Convolutional Neural Networks (R-CNN)- R-CNN is an object identification framework that first creates region suggestions, then extracts features from these proposals using a CNN, and then classifies and refines the proposals to identify objects and their specific locations in images.
- It’s a two-stage procedure that improves object detection accuracy greatly above previous methods.
Faster R-CNN (Region Convolutional Neural Network)- Faster R-CNN is a two-stage object identification method that combines a CNN-based classifier with a region proposal network (RPN).
- While somewhat slower than YOLO, it is more accurate. One might consider faster R-CNN to be the inventor of two-stage object detection.
YOLO (You Only Look Once)- The deep learning-based system YOLO is renowned for its efficiency and precision.
- It immediately predicts bounding boxes and class probabilities after dividing an image into a grid.
- YOLO models are designed to carry out real-time detection.
SSD (Single Shot MultiBox Detector)- One-stage object identification framework, SSD forecasts bounding boxes and class scores at various scales.
- It provides a nice balance between speed and accuracy and is quicker than Faster R-CNN.
RetinaNet- By utilizing a focus loss, RetinaNet overcomes the issue of class imbalance in object detection.
- Predicting item classes and bounding boxes uses a backbone network’s multilayer feature combination.
MobileNet- A lightweight Deep neural network architecture called MobileNet was created for effective mobile and embedded vision applications.
- While maintaining respectable accuracy for applications like image classification and object recognition, it uses depth-wise separable convolutions to decrease computation, making it quick and memory-efficient.
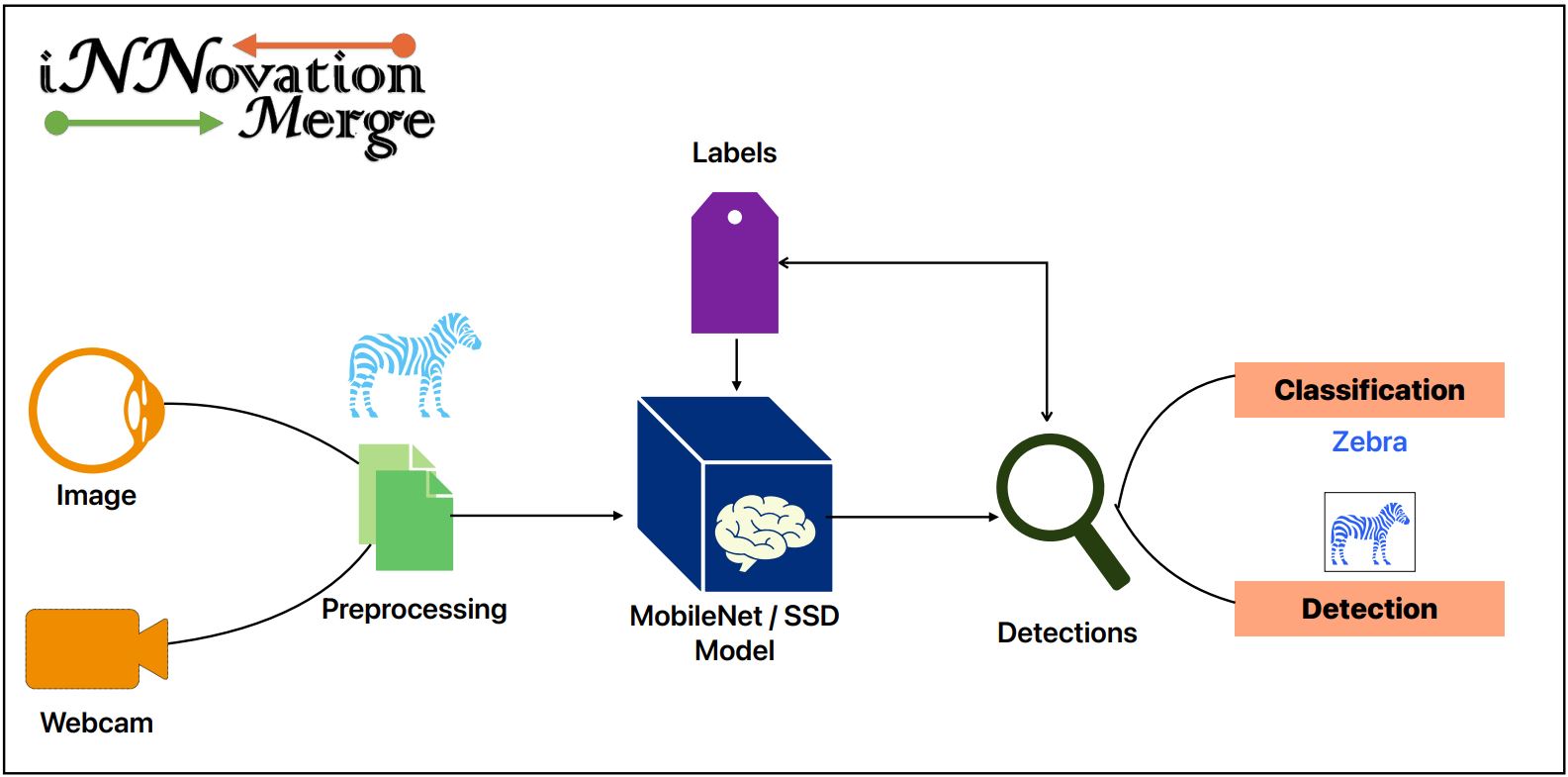
Object detection process
- Input Data: Receive an image or video frame as input.
- Feature Extraction: Extract relevant features from the input data that can be used to distinguish different objects.
- Object Localization: Determine the position of the objects within the image or frame. This is often done by predicting bounding boxes that tightly enclose each object.
- Object Classification: Assign a label or class to each detected object based on its appearance and features.
Block Diagram:
Clone and Run the project:
- This project uses the innovationmerge library internally for running object detection models which has core components required to build AI, IoT and other Applications.
- Pretrained models are downloaded from Official
TensorflowLink
Install library
Install on
Raspberry Pipip install poetry cd preditive_capture poetry installInstall on
Windowspip install poetry cd preditive_capture poetry add innovationmerge=1.1.2[windows]
Project Folder Structure
preditive_capture\Input- Input Files\Images are stored herepreditive_capture\Output- Output Files\Images are stored herepreditive_capture\models- Pre trained models are stored here
Detection 1 using MobileNet Pretrained Model
- Test with Image Detection
poetry run python mobilenet_main.py| Input | Output Image | Output Text |
 |
 |
|
- Predictive Capture using Raspberry Pi and Camera
- Detect objects using webcam
poetry run python mobilenet_main_web_cam.py - Detect objects and save an image when object is detected
poetry run python mobilenet_main_web_cam_save.py
Detection 2 using SSD MobileNet Pretrained Model
- Test with Image Detection
poetry run python ssd_main.py | Input | Output Image | Output Json |
| |
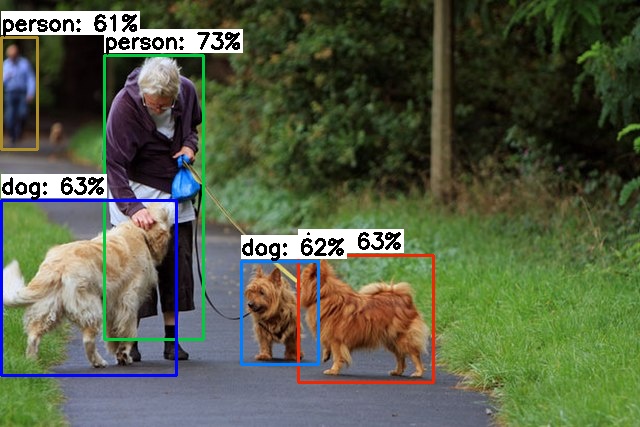 |
{'detection': [{'label_class_name': 'person', 'label_bounding_box': [{'x': 104, 'y': 55}, {'x': 203, 'y': 339}], 'confidence': 0.7383487}, {'label_class_name': 'dog', 'label_bounding_box': [{'x': 298, 'y': 255}, {'x': 433, 'y': 382}], 'confidence': 0.63895524}, {'label_class_name': 'dog', 'label_bounding_box': [{'x': 1, 'y': 200}, {'x': 176, 'y': 375}], 'confidence': 0.63582057}, {'label_class_name': 'dog', 'label_bounding_box': [{'x': 241, 'y': 261}, {'x': 318, 'y': 364}], 'confidence': 0.6227201}, {'label_class_name': 'person', 'label_bounding_box': [{'x': 1, 'y': 37}, {'x': 37, 'y': 149}], 'confidence': 0.613927}], 'processing_time': 0.042038679122924805} |
- Predictive Capture using Raspberry Pi and Camera
- Detect objects using webcam
poetry run python ssd_main_web_cam.py - Detect objects and save an image when object is detected
poetry run python ssd_main_web_cam_save.py
Watch below demo video to know how it works